
Database Replication - What, Why & How?
Cloud & Backend EP 13 - A Backend Developer's BFF

Database Replication means keeping a copy of your data on multiple machines.
It’s likely that the term comes from DNA replication that forms the basis of inheritance in biological organisms.
In distributed systems, replication increases the safety of your data. The more copies there are, the more resilient it is to destruction. But it also facilitates communication between the various replicas via the network.
Here’s a diagram that shows the concept of replication at a very basic level.
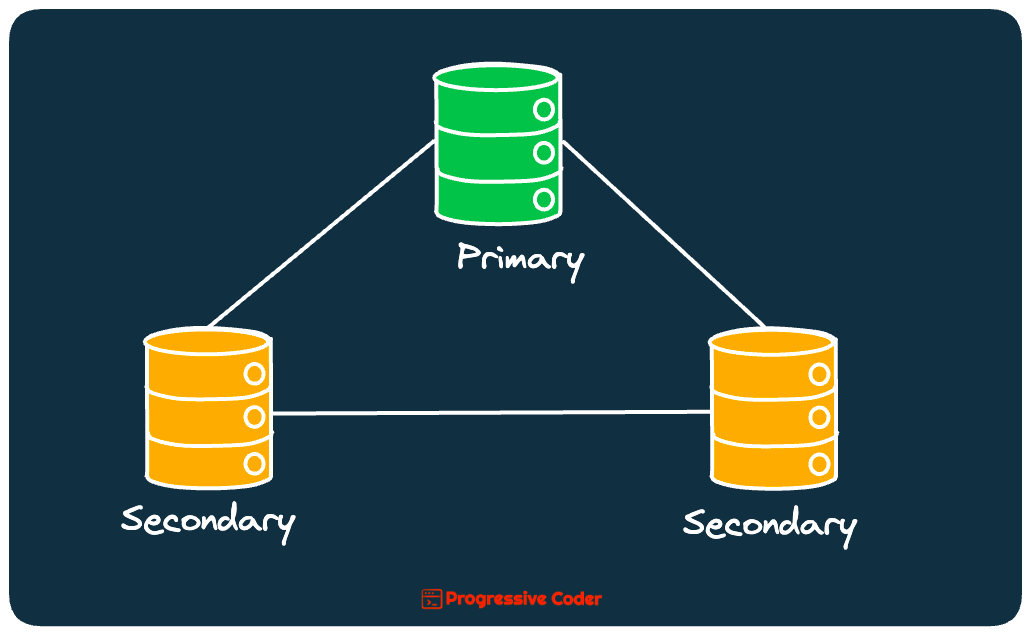
As you can see, the 3 replicas work in tandem with each other. They talk to each other over the network to provide significant benefits to your application.
Hello 👋 and welcome to a new edition of the Cloud & Backend newsletter.
I talked about replication in an earlier post. But it was more in context with sharding.

In this post, I discuss the WHAT, WHY & HOW of Database Replication.
🤖 Why Replication?
With the What out of the way, time to understand the Why of Database Replication.
Here are 5 main reasons why replication is a Backend Developer’s BFF:
👉 Data is Always There For You. Safe and Secure
In replication, there are multiple copies stored in different locations for redundancy.
Most databases support automatic failover so that the system can function properly even if some nodes are down.
With replication, you can chill and sip your coffee without worrying about data loss.
👉 Scaling Based on Demand
You can add nodes to increase capacity and throughput. Basically, this lets you scale your database horizontally for higher loads.
In other words, database replication takes care of your application during traffic spikes.
👉 Data Stays Close to the Action
With replication, your data stays close to your users. This improves performance and user experience by reducing latency.
Your users get a delightful lag-free experience. Ultimately, happy users mean paying users.
👉 No Instance Gets Overburdened
After replication, the read requests are distributed across multiple nodes. This allows you to scale your reads based on demand.
Replication turns your database into an Olympic relay team that shares the workload to achieve a singular goal.
👉 Backup In Case Things Go South
Replication protects your data in case of disasters that might bring down the primary instance. It ensures that a node going down does not erase your data.
In fact, Replication can bring the world back from the Thanos Snap.

With the WHAT & WHY of replication clear, time to look at HOW replication actually works.
🧰 How Replication Works?
The below diagram shows the most common approach to Replication.

Each node or instance that stores a copy of the data is known as a replica. In the illustration, we have 3 replicas - 1 green and 2 yellow.
Every write to the database should reach every replica. Otherwise, there’s no point in replication.
The most common approach to get this done is Leader-Based Replication. You may know it by other names such as Active/Passive or Master-Slave Replication. All of them are basically the same thing.
In the figure, the green replica is the Leader node while the others are Followers.
Here’s what happens under the hood.
👉 In this style of replication, clients send all their write requests to the leader node. The leader writes the new data to its local storage.
👉 The leader also sends the data change to all its followers in the form of a replication log or change stream.
👉 Each follower reads the log and updates its local copy of the database to bring it up to speed.
👉 When a client wants to read data from the database, it can send the query to the leader or any of the followers as well. This is usually done automatically using load balancers.
⏰ Leader-based replication may sound intimidating. But modern database systems abstract it for the clients. PostgreSQL, MySQL, MongoDB, and other databases all have replication as an in-built feature.
In fact, distributed message brokers such as Kafka and RabbitMQ also provide this capability out of the box.
🪁 Types of Replication
There are two main types of replication:
Synchronous
Asynchronous
👉 In Synchronous Replication, the leader waits until all followers have confirmed that they have received the write before reporting success to the user.
👉 In Asynchronous Replication, the leader sends the updates to the followers, but does not wait for a response from the follower.
As you can notice, synchronous replication guarantees that followers will have an up-to-date copy of the data. However, this comes at the cost of the whole system going down even if one follower goes down.
Asynchronous replication gets around this issue by making the leader free to process new write operations. However, this comes at the cost of a write operation not guaranteed to be durable even if it has been confirmed to the client.
Ultimately asynchronous replication can also lead to the problem of eventual consistency. But more on that in a later post.
🏀 Over To You
Have you ever used replication in your database?
If yes, what were the challenges you faced?
And what were the benefits?
Write your thoughts in the comments section.
If you are finding this newsletter valuable, consider sharing it.
Progressive Coder grows thanks to word of mouth. Share the article with your friends or colleagues to whom it might be useful.
Wishing you a great weekend ahead! ☀️
See you later.