
How Uber Eats Deals with Duplicate Images?
Plus an Intro to Staff+ Engineer Roles

Hello 👋 and welcome to a new edition of the Progressive Coder newsletter.
In today’s edition, we talk about:
🧰 How Uber Eats Avoids Duplicate Images?
🤖 Staff+ Engineers and What They Do?
⏰ Some Interesting Tweets
To support Progressive Coder, share it with your friends and colleagues.
🧰 Uber Eats versus Duplicate Images
Uber Eats handles millions of product images every single hour. That’s an insane scale when you think about it.
At this scale, duplicate images can burn a hole through your pocket in multiple ways:
Increased processing costs
Greater storage costs
Higher CDN costs
Not handling duplicate images is like not fixing the leak in your boat while traveling through the ocean. Sooner or later, you are going to sink.
So - how did Uber Eats deal with duplicate images?
👉 The first solution was quite basic. It involved 3 steps:
downloading
processing
and storing the image URLs.
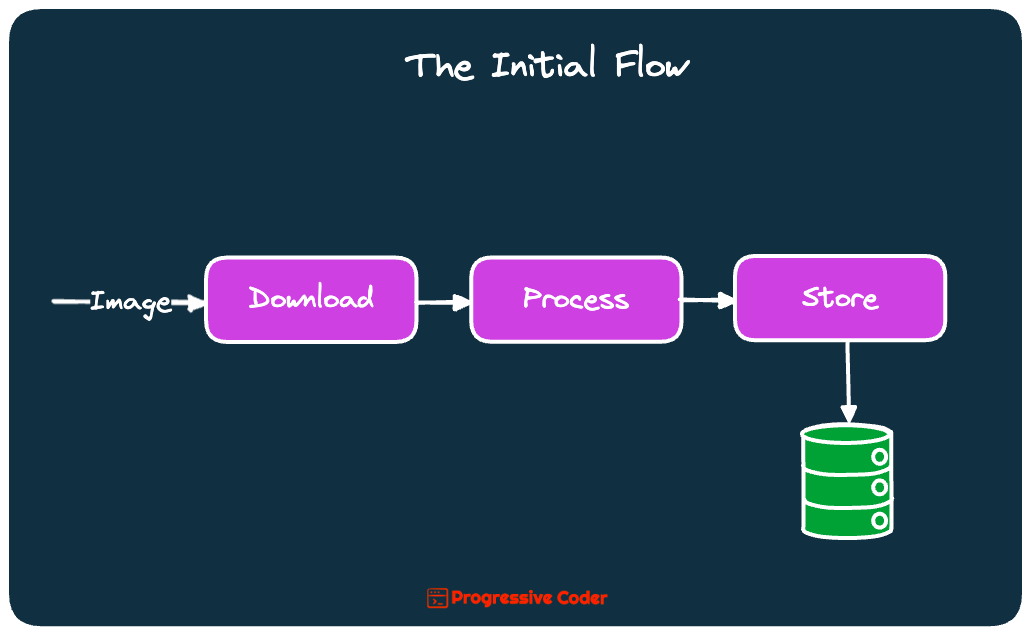
There was no de-duplication whatsoever. Also, no reuse of images.
To achieve de-duplication, the team at Uber decided to push more responsibility to the backend service.
Three main flows were identified:
✅ Known and Processed Image
✅ New and Unprocessed Image
✅ Known but Not Processed Image
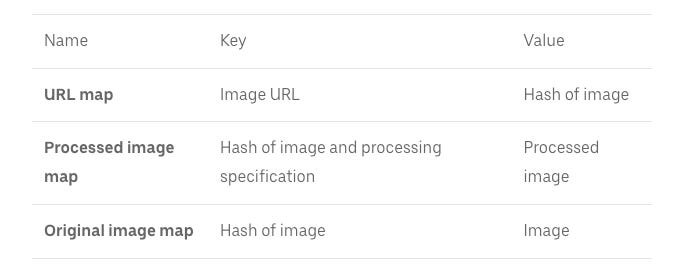
To implement these flows, they relied on 3 separate maps:
URL Map
Processed Image Map
Original Image Map
If you aren’t aware, maps are just key/value pairs that let you fetch data based on a key with constant time complexity.
The below table shows the structure of each map.
The images were stored in Uber’s blob storage system known as Terrablob (similar to Amazon S3). The metadata was stored in Docstore.
What about the 3 flows? How were they implemented?
Let’s find out👇
👉 Known and Processed Images
Input is the Image URL.
Get hash from the URL Map.
If found, check for the hash in the Processed Image Map.
If found, return the Processed Image URL.
That’s it. No new upload in this case.
This is the simplest flow. Duplicate images are handled like a boss!
Here’s an illustration for the same.

👉 New and Unprocessed Image
Input is once again the Image URL.
Get hash from the URL Map.
Not Found. Download the image and get the hash.
Update the URL Map and Original Image Map with the data.
Process image and update Processed Image Map.
Return the Processed Image URL.
This is the longest flow and takes care of completely new images coming into the system.
The below illustration shows the process.

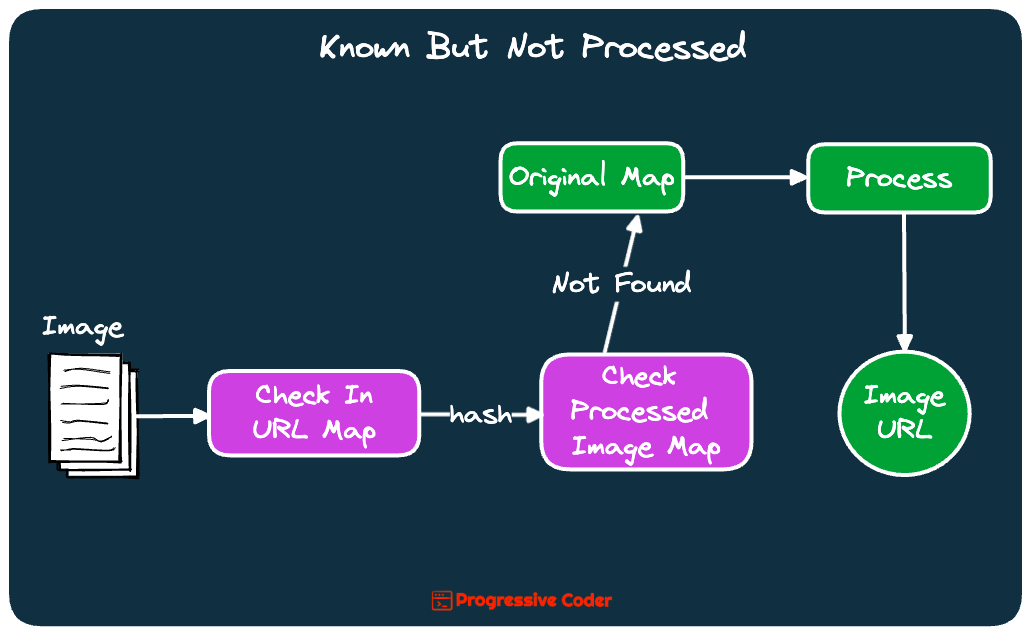
👉 Known But Not Processed Image
Input is the Image URL.
Get hash from the URL Map.
Found. Check Processed Image Map.
Not found. Process the image and store it.
Return Processed Image URL.
This is less complex than the previous flow. Kind of like the middle ground.
Here’s an illustration.
🚀 Together, the 3 flows prevent duplicate images from entering the Uber Eats system and ultimately generate crucial cost savings.
🤖 What do Staff+ Engineers Typically Do?
Staff+ Engineers is a completely separate path for growth in a tech organization.
You typically get a chance to join the Staff+ engineering path after becoming a senior engineer.
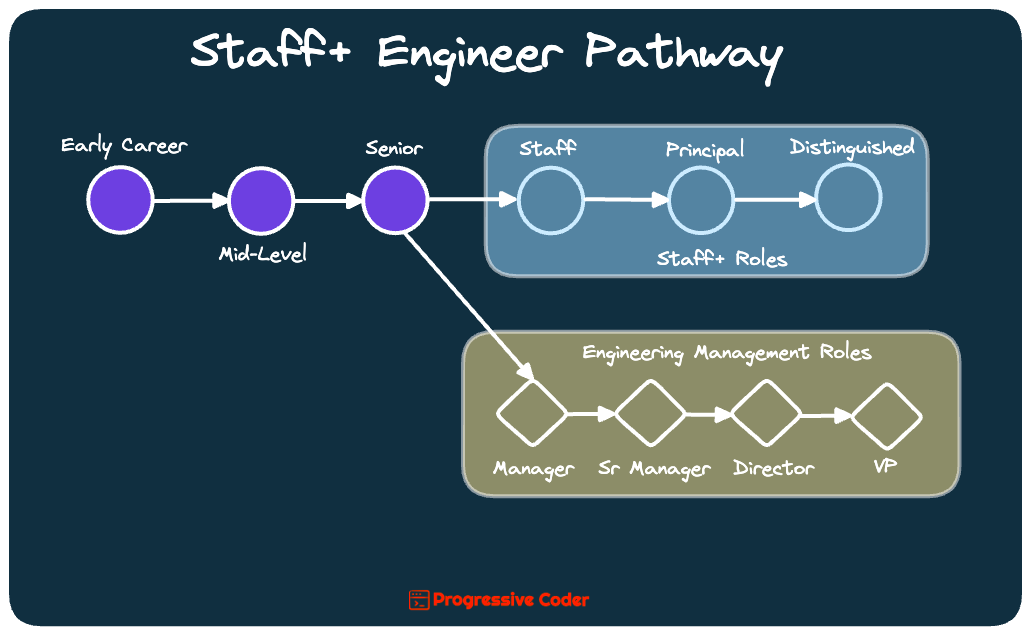
But what do Staff+ engineers typically do? 🤔
From the amazing book Staff Engineer-Leadership Beyond the Management Track, the Staff+ engineers focus on projects or efforts that have strategic value for the company.
As a senior engineer, you are expected to build relationships, write software and coordinate complex projects.
The same is expected of a Staff+ engineer as well along with a bunch of other responsibilities such as:
Setting the technology direction of the product.
Providing sponsorship and mentorship to other members of the team.
Bringing engineering context to business problems.
Exploration of new ideas and opportunities.
Being the glue of the team.
To compress all of it, you could think of Staff+ Engineers as part-time product managers for technology.
⏰ Some Interesting Tweets
👉 Not totally tech-related, but a very valid idea in multiple life contexts. Going all in sounds easy and inspiring but is seldom an effective strategy for achieving success. You can dramatically increase your odds of reaching your goal if you can survive a bunch of setbacks. Sometimes, survival is more important
👉 ChatGPT is far from perfect and prone to hallucinations. It is better to use it as a learning partner rather than a teacher.

👉 It’s not useful to go overboard with implementing principles like SOLID. In most applications, it does more harm than good.

🏀 Over To You
Have you handled duplicate images in your system? If yes, what approach did you use?
What kind of levels do you have in your organization?
Which tweet did you find the most insightful?
Write your thoughts in the comments section.
Progressive Coder grows thanks to word of mouth. Share the article with your friends or colleagues to whom it might be useful.
Wishing you a great week ahead! ☀️
See you later.