

How to scale your relational database?
How to scale your relational database?
Cloud & Backend EP 6 - Sharding vs Replication

Hello 👋 and welcome to a new edition of the Cloud & Backend newsletter.
Every Tuesday, I will send you an email like this with actionable advice on a topic related to Cloud & Backend development.
The topic for today - How to scale your relational database?
To support Progressive Coder, consider subscribing if you haven’t already done so.
Yes, you can scale out relational databases.
But isn’t that cumbersome?
Of course, it’s much simpler to have a relational database running on a single machine. You scale it up as necessary by adding more computing resources.
However, a non-distributed database will always be limited in storage and computing power.
So, how can you scale a relational database?
Let’s find out.
🚀 Sharding vs Replication
Sharding and replication are two valuable techniques to scale your database.
👉 Sharding involves partitioning data across multiple servers based on a specific key.
Each server on the shard stores a portion of the data. Queries are routed to the appropriate server based on the key.
Here’s an illustration showing the concept of sharding.
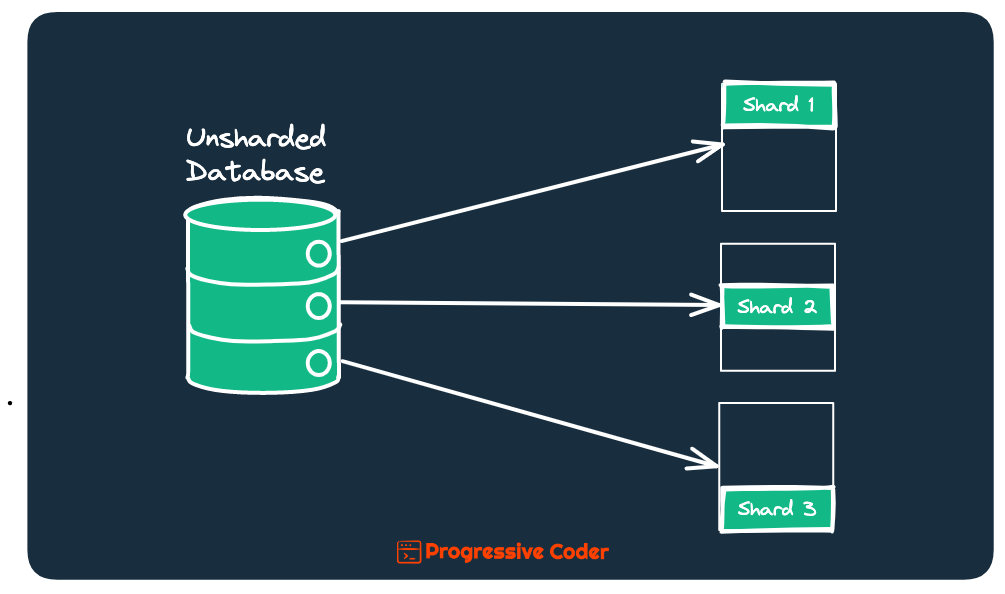
Sharding helps you horizontally scale your database (also known as scaling out) by adding more machines to an existing stack.
Think of these machines as helpers that share the overall workload while letting your application handle more work in general.
The shards are autonomous and don’t share data or computing resources.
This reduces query times as your queries have to run on fewer data. It also increases overall reliability because you don’t have all your eggs in one basket.
👉 Replication involves creating multiple copies of the database with each copy running on a different server.
These copies are identical and changes made to one copy are propagated to the others.
Here’s what it looks like.
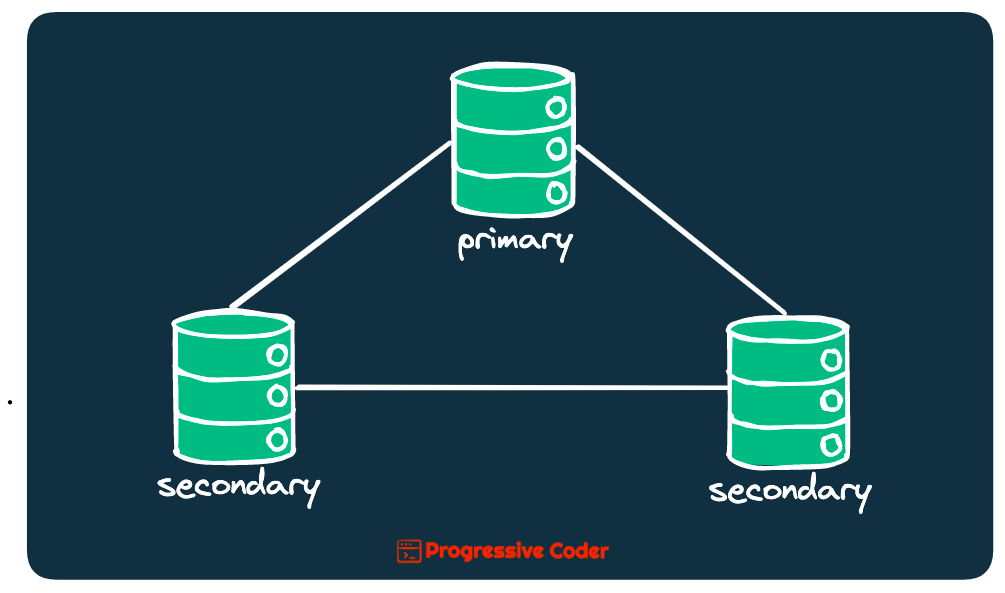
Replication helps you achieve high availability and boosts reliability. I explained this concept in a recent post about designing a high-availability system.
However, replication also helps scale your read operations since read requests can be handled by multiple servers.
🤖 How to choose the right approach?
Go for sharding if…
👉 You have large-scale applications with high-data throughput.
Think of social media platforms, online marketplaces and gaming apps. Since these apps need to handle high data volumes, sharding helps them distribute the load across multiple servers.
👉 You have a global application with multiple geographic regions.
In this scenario, you can shard the data based on geographic location. This ensures that users are always accessing data from servers that are geographically closer to them. In return, you get improved performance and reduced latency.
Go for replication if…
👉 You have an application that requires high-availability.
Think of a mission-critical application such as a system running a hospital or an airline. In such cases, replication can be a lifesaver.
If one server goes down, the application can switch to another server with a copy of the data. This means less downtime and improved availability.
👉 You have an application with a read-heavy workload.
Think of social media apps like Twitter and Discord.
By creating multiple copies of data, the application can distribute read requests across multiple servers.
This makes me think. Are these two concepts mutually exclusive?
Not really! You can also use them both together.
Go for both sharding and replication if…
👉 You have a large-scale global application that also needs to be highly-available.
Think of a ride-sharing application like Uber or a social media platform like Instagram.
Platforms like these typically have millions of users all across the globe and they also need to be available and responsive all the time.
In such cases, you can use sharding to distribute the data across multiple servers based on geographic location. However, you will also replicate each shard to ensure high-availability.
👉 You have an application with varying read and write workloads.
Think of an e-commerce website having a large number of product listings that must be updated frequently. This leads to more writes to the database.
However, most users only browse and search for products resulting in a higher number of read operations.
In this scenario, you can leverage sharding to distribute the write operations across multiple servers. Then, you can scale the read operations by replicating the shards.
🕹️ Over to you
Do you use sharding or replication or any other technique to scale your databases?
If yes, what technique do you prefer the most in a given situation?
Write your answers in the comments section below.
Industry Round-Up
Here are a few things that might interest you:
The AI Race is heating up. Microsoft has introduced AI for excel and outlook.
GitHub is trying to reimagine the developer experience with the launch of GitHub Copilot X. I wonder how that will turn out 🤔
The current global economy is impacting IT budgets. 83% of CIOs say they are under pressure to make their budgets stretch further than ever before. The key focus is on cloud cost management and handling technical debt. Have your projects been impacted because of budget constraints?
Go enters Tiobe’s list of top 10 programming languages. Is anyone learning or using Go in our little community?
AWS Application Composer is now generally available. You can use it to build serverless applications using a visual interface.
Finally, I stumbled across a little funny secret this week - the first behind-the-scenes look into ChatGPT’s complicated backend 😉


And that’s it for today!
If you are finding this newsletter valuable, consider doing any or both of these:
👉 Support the Newsletter - if you haven’t done so already, consider becoming a paid subscriber.
👉 Share it - Progressive Coder grows thanks to word of mouth. Share the article with your friends or colleagues to whom it might be useful!
Wishing you a great week ahead! ☀️
See you later.